Configuring Cluster Database Replication
The gateway cluster depends on a reliable MySQL database. The standard mechanism uses the MASTER-MASTER replication, in which each node is a SLAVE of the other node. Any changes to either database node are automatically replayed in the other database. This ensures that an up-to-date database is always available for the processing nodes of the Gateway cluster. In this configuration, one node is considered the “Primary” database, while the other node the “Secondary” (or “Failover”) node.
gateway
The
CA API Gateway
cluster depends on a reliable MySQL database. The standard mechanism uses the MASTER-MASTER replication, in which each node is a SLAVE of the other node. Any changes to either database node are automatically replayed in the other database. This ensures that an up-to-date database is always available for the processing nodes of the Gateway cluster. In this configuration, one node is considered the “Primary” database, while the other node the “Secondary” (or “Failover”) node. Database replication applies to Appliance Gateways only. It does not apply to Software Gateways.
During normal operation, all Gateway processing devices connect to the Primary database. If the Primary database fails, then all nodes switch to the Secondary database.
Regardless of the number of Gateway processing nodes in a cluster, a maximum of two MySQL database servers can be configured for database replication in a Gateway cluster (for example, "DBServer1" and "DBServer2"). Each peered database unit becomes both a slave and master to the other unit. The Gateway cluster uses one as the Primary database node and then fails over to the Secondary database node in case of problems.
Background replication between the database nodes occurs constantly, with updates to the Secondary Node happening milliseconds after the primary node. If the Primary Node fails, then the Gateway processing nodes invalidates previous connections to that database node before automatically connecting to the Secondary Node.
IMPORTANT:
You should configure replication first, before configuring any Gateway nodes. If you already configured a node before replication is set up, do the following steps to recover before configuring replication:- Configure the secondary Gateway node as if it was a standalone node. See Configuring the First Processing Node. Use all the same credential information as the first node to ensure that the grants are set up correctly on the local database.
- Once this is done, return to the Gateway main menu and then select option2("Display CA API Gateway configuration menu"), then option3("Configure the CA API Gateway"). See Gateway Configuration Menu (Appliance). Point the database to the primary node and ensure that the secondary database is set up.
Contents:
Prerequisites
Ensure that you have:
- Host names for DBServer1 and DBServer2 are configured in DNS or "/etc/hosts"; you may use IP addresses instead of hostnames
- MySQL service for DBServer1 and DBServer2 is running
- Both Gateway services are stopped
- Time synchronization is configured for all the Gateway nodes
Replication Flow
When a change is made to a MASTER database, the replication configuration replays the change in the SLAVE database. The following diagram illustrates the replay mechanism.
The diagram only describes one "direction" of the MASTER-MASTER replication story. Full replication includes an identical flow in the reverse direction.
Replication_flow
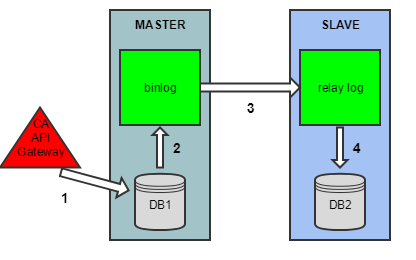
Notes:
- A change is made to the MASTER database (INSERT, UPDATE, ALTER, etc).
- MASTER writes change to binlog.
- IO thread on SLAVE reads change from binlog and writes to relay log.
- SQL thread on SLAVE reads change from relay log and writes to SLAVE data.
How to Configure Replication
- Run the following script against the local database on each node of the cluster:# /opt/SecureSpan/Appliance/bin/add_slave_user.shTheadd_slave_user.shscript adds permissions for the users to MySQL.Enabling replication requires changes to the/etc/my.cnffile. There are four lines in the file that pertain to replication, all of which are commented out in a newly-installedCA API Gateway. When you run theadd_slave_user.shscript, it enables these lines and restarts the MySQL daemon.The four lines in question are grouped within the/etc/my.cnffile on the Gateway appliance:# Uncommment log-bin, log-slave-update and log_bin_trust_function_creators# if a clustered db serverlog-bin=/var/lib/mysql/ssgbin-loglog_bin_trust_function_creators=1log-slave-update# uncomment the next item on 1st db master serverserver-id=1# uncomment the next item on 2nd db master servers# server-id=2Each line is described below:
- log-binsets up the location of the binary replay log on a MASTER system
- log_bin_trust_function_creatorscontrols whether stored function creators can be trusted not to create stored functions that causes unsafe events to be written to the binary log
- Log-slave-updateinstructs the SLAVE to create its own binary replay log for all changes made if a slave chain is configured (A → B → C)
- server-idis set to a unique identifier for the node in the replication scenario
For more information, refer to the MySQL documentation at: http://dev.mysql.com/doc/refman/5.0/en/ - Complete the following prompts in the script:
- Enter hostname or IP for the <target>:Enter the hostname for the target machine being configured. In almost all cases, this is the other peer node. For example, if running theadd_slave_user.shscript on the primary node, you enter the hostname of the secondary node.Note:Hostnames are preferable to prevent DNS resolution issues. Use an IP address only if the hostname is not known.
- Enter replication user:Enter the user account in the MySQL database that is used for replication. The default username isrepluser.
- Enter replication password:Enter the password for the replication user.
- Enter MySQL root user:Enter the user account for the root MySQL user.
- Enter MySQL root password:Enter the user account for the root MySQL password.
- Is this the Primary (1) or Secondary (2) database node?Enter1or2to indicate the type of node.
- Run the following script against each database node of the cluster:# /opt/SecureSpan/Appliance/bin/create_slave.shThecreate_slave.shscript sets up the replication to run between the two databases, using the user configured inadd_slave_user.sh.Thecreate_slave.shscript is always run against the other node in a two-node database cluster. In other words, you are setting up the other node as the MASTER. Since this script is run on both nodes, each node gets the other one set up as its master, thus creating the MASTER-SLAVE relationship.
- Complete the following prompts in the script:
- Enter hostname or IP for the MASTER:Enter the hostname for the target machine being configured. In almost all cases, this is the other peer node. For example, if running thecreate_slave_user.shscript on the primary node, you would enter the hostname of the secondary node.Note:Hostnames are preferable to prevent DNS resolution issues. Use an IP address only if the hostname is not known.
- Enter replication user:Enter the account that is used in MySQL for replication. This should be the same user as entered when configuring the replication user in the first script (add_slave_user.sh).
- Enter replication password:Enter the password for the replication user.
- Enter MySQL root user:Enter the user account for the root MySQL user.
- Enter MySQL root password:Enter the user account for the root MySQL password.
- Do you want to clone a database?
- If you have a pre-existing database and wish to keep its contents, enteryesand then enter the name of the database to clone. Be sure the slave is not currently running on the MASTER.
- If you are following these steps for the first time or if you want to discard the existing database and create a new one, enterno.